Project: Chat Bots in Customer Service
7 minute read
![]()
![]() Status: final , Type: Project
Status: final , Type: Project
Anna Everett, sp21-599-355, Edit
Abstract
Automated customer service is a rising phenomon for buisnesses with an online presence. As customer service bots advance in complication of problems they can handle one concern about the altered customer experiece is how the information is conveyed. Using customer support data tweets on twitter this project runs sentiment analysis on it customer tweets and then train a convolutional neural network to examine if conversation tone can be detected early in the conversation.
Contents
-
Introduction
-
Procedure
- The Dataset
- Simplifying the dataset
-
The Algorithm
- Sentiment Analysis Overview and Implementation
- Convolutional Neural Networks (CNN)
- Spliting Up the Data
-
Training the Model
-
Conclusion
-
References
Keywords: AI, chat bots, tone, nlp, twitter, customer service.
1. Introduction
Please not ethat an up to date version of these instructions is available at
Some studies report that customers prefer live chat for their customer sevice interactions1. Currently, most issues are simple enough that they can be resolved by a bot; and over 70% of companies are already using or have plans to use some form of software for automation. Existing Ai’s in use are limited to simple and common enough questions and or problems that allow for generalizable communication. As AI technology develops and allows it to handle more complicated problems the communication methods will also have to evolve.
 Fig 1: Customer Support Preferences 1
Fig 1: Customer Support Preferences 1
An article by Forbes “AI Stats News: 86% Of Consumers Prefer Humans To Chatbots”, states that only 30% of consumers beleve that an AI would be better at solving their problem than a human agent 2. Human agents are usually prefered becuase humans are able to personalize converstaions to the indiviual customer. On the other hand, automated software allows for 24/7 assistance if needed, the scale of how many customers a bot would be able to handle is considered larger and more efficient in comparision to what humans can handle, and a significant amount of questions are simple enough to be handled by a bot 3.
 Fig 2: Support Satisfaction Image source
Fig 2: Support Satisfaction Image source
To get the best out of both versions of service, this project uses natural language processing to analyze social media customer service conversations. This is then run through a convolutional neural network to predict if tone can be determined early in the converstaion.
2. Procedure
2.1 The Dataset
The dataset comes from the public dataset compilation website, kaggle, and can be found at Kaggle Dataset. This dataset was chosen due to twitter support’s informal nature that is expected to come with quicker and more automated customer interactions.
The content of the data consists of over 2.5 million tweets from both customer and various companies that have twitter account representation. Each row of data consists of: the unique tweet id, an anonymized id of the author, if the tweet was sent directly to a company, date and time sent, the content of the tweet, the ids of any tweets that responded to this tweet if any, and the id of the tweet that this was sent in response to if any.
2.2 Simplifying the Dataset
The raw dataset is large and contins unncessery information that isn’t needed for this porpose. In order to trim the dataset only the first 650 samples are taken.
Next, since the project goal is to predict customer sentiment any tweet and related data sent by a company is removed. Luckily, companies author id’s don’t get anonymized and therefore we can filter those out by removing any data associated with an author id that contains letters. For speed and simplicity these author id are only checked for vowels.
3. The Algorithm
3.1 Sentiment Analysis Overview and Implementation
Sentiment analysis is the process of taking in natrual language text and determining if it has a positive or negative sentiment 4. This process is useful for when doing market research and tracking attitudes towards a particualar company. In a similar fashion this project uses sentiment analysis to determine the text sentiment of the customer initially with their first inquiery and also the sentiment of their side of the conversation as a whole.
The goal of analyzing both the first and general tone of the text is to determine if a general correlation between them can be found.
The main library used for the sentiment analysis of the data was “nltk” and its subpackage “SentimentIntensityAnalyzer”
 Fig 3: Customer Sentiment Distribution
Fig 3: Customer Sentiment Distribution
As can be seen in the Fig 3 the distribution of the sentiment values are generally on a normal distribution. Looking at the binary classifications of both the first and average sentiment distribution it can be seen that while the majority can be classified as positive, 1, there’s still a significant amount that are classified as negative, 0.
3.2 Convolutional Neural Networks (CNN)
While convolutional Neural Networks are traditionally used for image processing. Some articles suggest that CNN’s also work well for Natural Language Processing. Traditionally, convolutional neural networks are networks that apply filters over a dataset of pixels and process the pixel as well as those that surrounds it. Typically this is used for images as pictured below in Fig 4, for filtering and edge detecting for identifying objects.
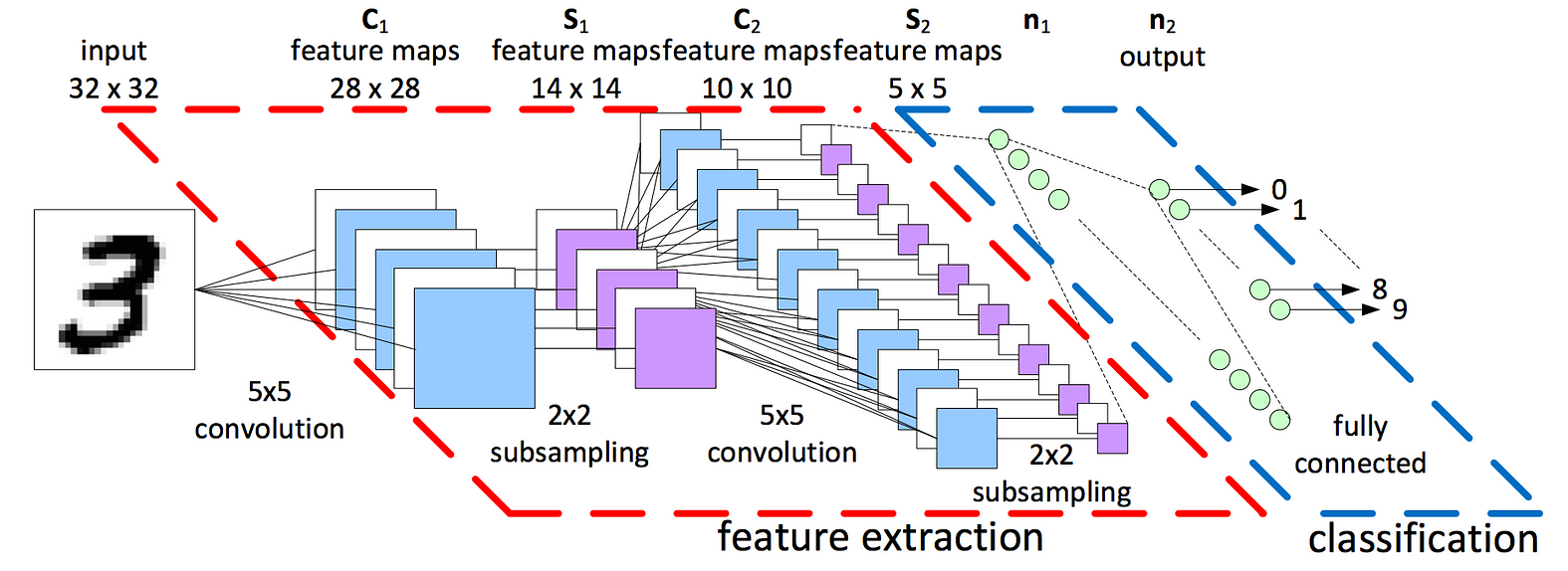 Fig 4: Image convolution Image source
Fig 4: Image convolution Image source
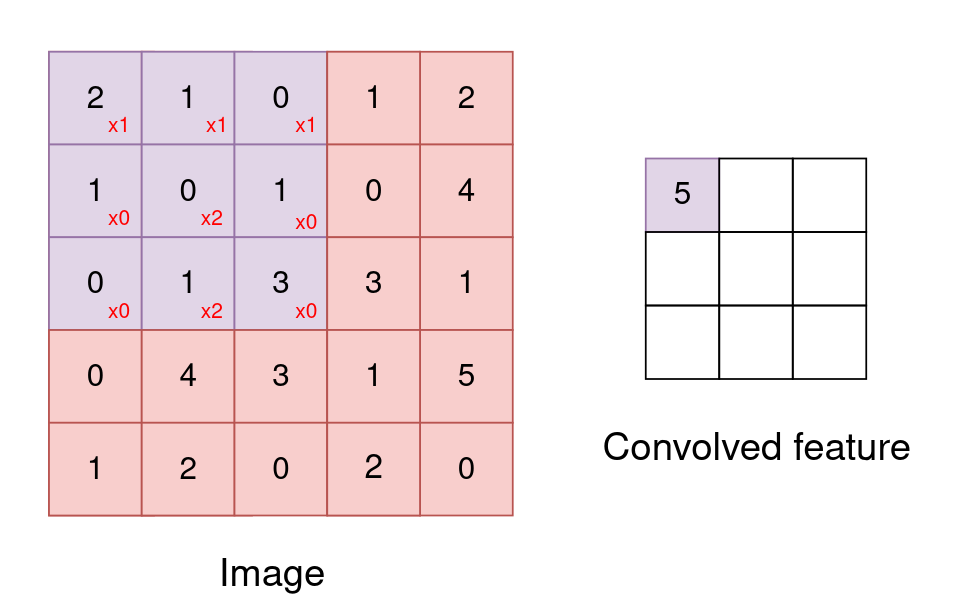 Fig 5: Convolution Visual Image source
Fig 5: Convolution Visual Image source
CNN’s also work well for natrual language processing. Thinking about the english language, meaning and tone of a scentence or text is caused by the relation of words, rather than each word on its own. NLP through CNNs work in a similar fashion to how it processes images but instead of pixels its encoded words that are being convolved.
As can be seen by Fig 6, this project used a multi-layered CNN: beginning with an embedding layer, alternating keras 1 dimension convolution and max pooling layers, a keras dropout layer with a rate of 0.2 to prevent overfitting of the model5 and a keras dense layer that implements the activation function into the output 5.
 Fig 6: CNN Model
Fig 6: CNN Model
3.3 Splitting Up the Data
In order for the data to be suitable to be run through the CNN the input features must be reshaped into a 2-D array. Afterwards the data was split up using the “sklearn.model_selection” package “train_test_split” with the features being input as the encoded tweets and the lables being input as the general classification sentiment.
4. Training the Model
The model was trained using the training text and training sentiment, because of the small samples used a batch size of 50 was input and run for 10 epochs.
5. Conclusion
In conclusion, while sentiment prediction of customer tweets were not able to be executed there is still useful information found to aid in future attempts. In dealing with the informal raw twitter data ad performing a non-binary sentiment analysis allowed for visualization of the true spread of what can be expected when anticipating dealing with customers, especially in an informal setting such as social media. This project also brought to light the theorectial versatility of convolutional neural networks, though not further examined in this project. Using the model model fit as an indication, there is reasonable evidence that the first inquiry will be enough to predict and take proactive measures in future customer service chat bots. Future execution of this project should include altering the data pre-processing technique and using a larger set of samples from the dataset.
6. References
-
Super Office, [online resource] https://www.superoffice.com/blog/live-chat-statistics/ ↩︎
-
Forbes, [online resource] https://www.forbes.com/sites/gilpress/2019/10/02/ai-stats-news-86-of-consumers-prefer-to-interact-with-a-human-agent-rather-than-a-chatbot/?sh=5f5d91422d3b ↩︎
-
Acuire, [online resource] https://acquire.io/blog/chatbot-vs-live-chat/ ↩︎
-
Monkey learn, [online resource] https://monkeylearn.com/sentiment-analysis/ ↩︎
-
Keras, [online documentation] https://keras.io/api/layers/regularization_layers/dropout/ ↩︎